Claude Code Workflows 深度解析:把编排写进脚本之后
这东西是昨天(2026 年 5 月 28 日)才放出来的,和 Opus 4.8 一起,目前还是 research preview。它能解决一个老问题:一个对话窗口指挥不动太多 agent。下面不讲源码,只讲它到底改了什么、什么时候用划算、什么时候纯属浪费 token。
先把它放回坐标系里
在 workflow 之前,Claude Code 里已经有两种"多步干活"的方式:subagent 和 skill。三者都能跑多步任务,真正的区别只有一句话——plan 攥在谁手里。
| Subagent | Skill | Workflow | |
|---|---|---|---|
| 本质 | Claude 派出去的一个 worker | Claude 照着念的一份说明 | runtime 执行的一段脚本 |
| 谁决定下一步 | Claude,一轮一轮地决定 | Claude,照 prompt 走 | 脚本本身 |
| 中间结果放哪 | Claude 的上下文 | Claude 的上下文 | 脚本里的变量 |
| 能复现的是 | worker 的定义 | 那份说明 | 整套编排逻辑 |
| 规模 | 每轮几个委派 | 同左 | 每次几十到几百个 agent |
| 被打断 | 整轮重来 | 整轮重来 | 同会话内可续跑 |
用 subagent 和 skill 时,Claude 是那个调度员:它一轮一轮决定接下来 spawn 什么,每个结果都回流进它的上下文。窗口一长,上下文就被中间产物撑爆,它自己也开始记不清前面派了谁、谁回了什么。
workflow 把调度这件事从对话里搬进了代码。循环、分支、中间结果,全在脚本变量里待着,Claude 的上下文只接最后那个答案。这是它和前两者最本质的差别,也是它能扩到几百个 agent 而不乱的原因。
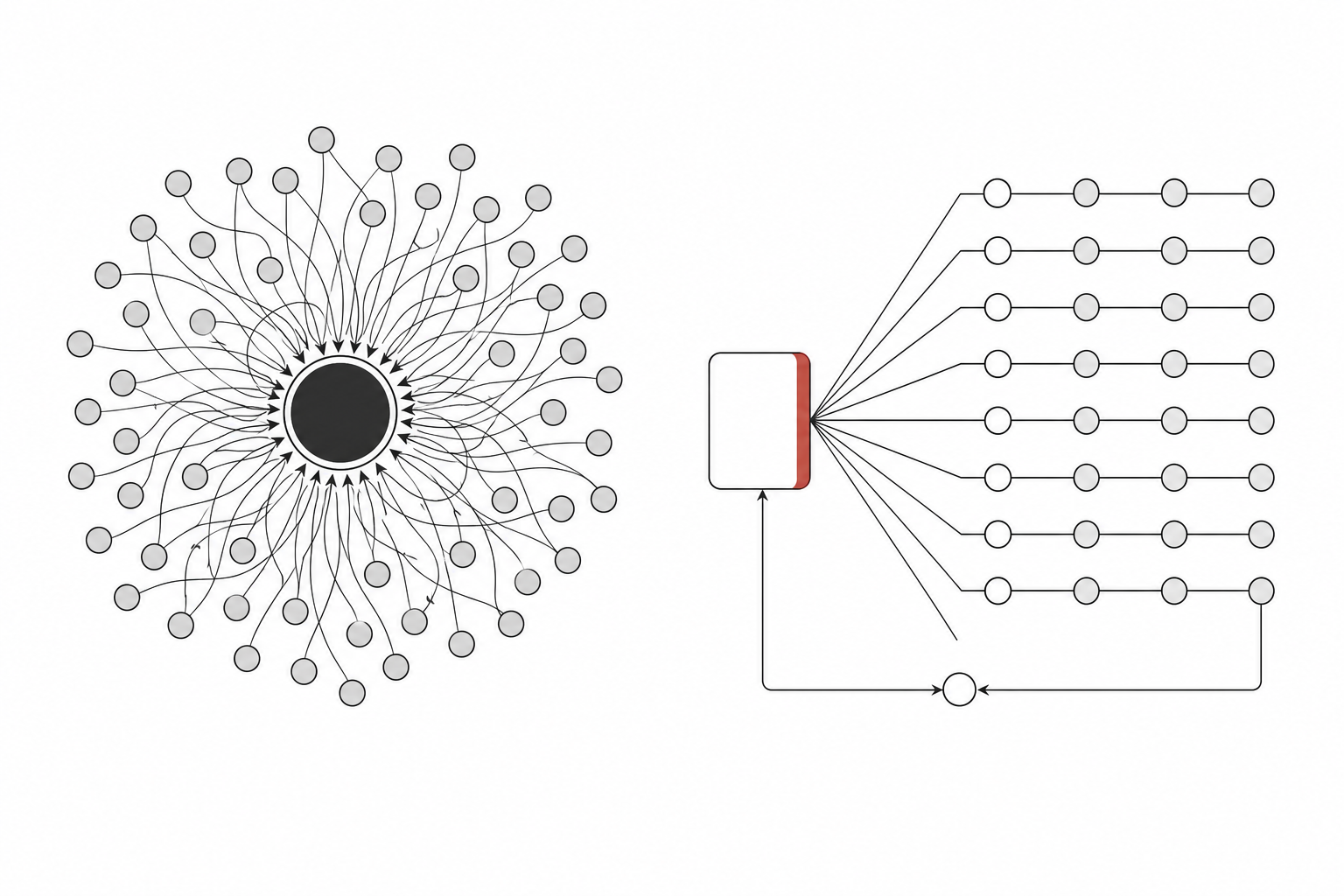
"把 plan 写进代码"换来了什么
除了上下文干净,搬进代码还带来两件靠堆 agent 数量换不来的东西。
一是可复现。脚本就是编排本身。一段"每条分支都先各跑各的、最后再汇总去重"的逻辑,这次跑和下次跑是同一段代码,而不是 Claude 临场又想了一遍。每个分支的 review 跑完一条就接着验一条,慢的那条没拖住快的。
二是能上质量模式,而不只是跑得更多。因为编排是代码,你可以让几个互相独立的 agent 对抗式地审查彼此的发现——一条结论得过多数票才算数;也可以让它从几个不同角度各起一版方案,互相比完再挑一版提交。这是单趟跑拿不到的可信度。
pipeline 还是 parallel:别上来就加屏障
真正写脚本时,最常踩的判断是这个。两种跑法:
- pipeline(默认):每个条目独立穿过所有阶段,阶段之间没有屏障。A 条目可以已经在第 3 阶段,B 条目还在第 1 阶段。墙上时间约等于最慢的那一条链,而不是"每阶段最慢之和"。
- parallel(屏障):等所有任务全跑完才往下走。
多阶段任务的默认应该是 pipeline。只有当"第 N 阶段真的需要第 N-1 阶段所有结果一起到位"时,屏障才成立——比如全量去重后再做下游的昂贵验证、或者总数为零就整段跳过。
不成立的理由也很常见:"我得先 flatten/filter 一下"——这放进 pipeline 的某个阶段里做就行;"两个阶段概念上是分开的"——分开不等于要同步。如果五个 finder 并行,最慢的是最快的三倍,一个屏障就白白浪费了那些快 finder 三分之二的空闲。拿不准时,选 pipeline。
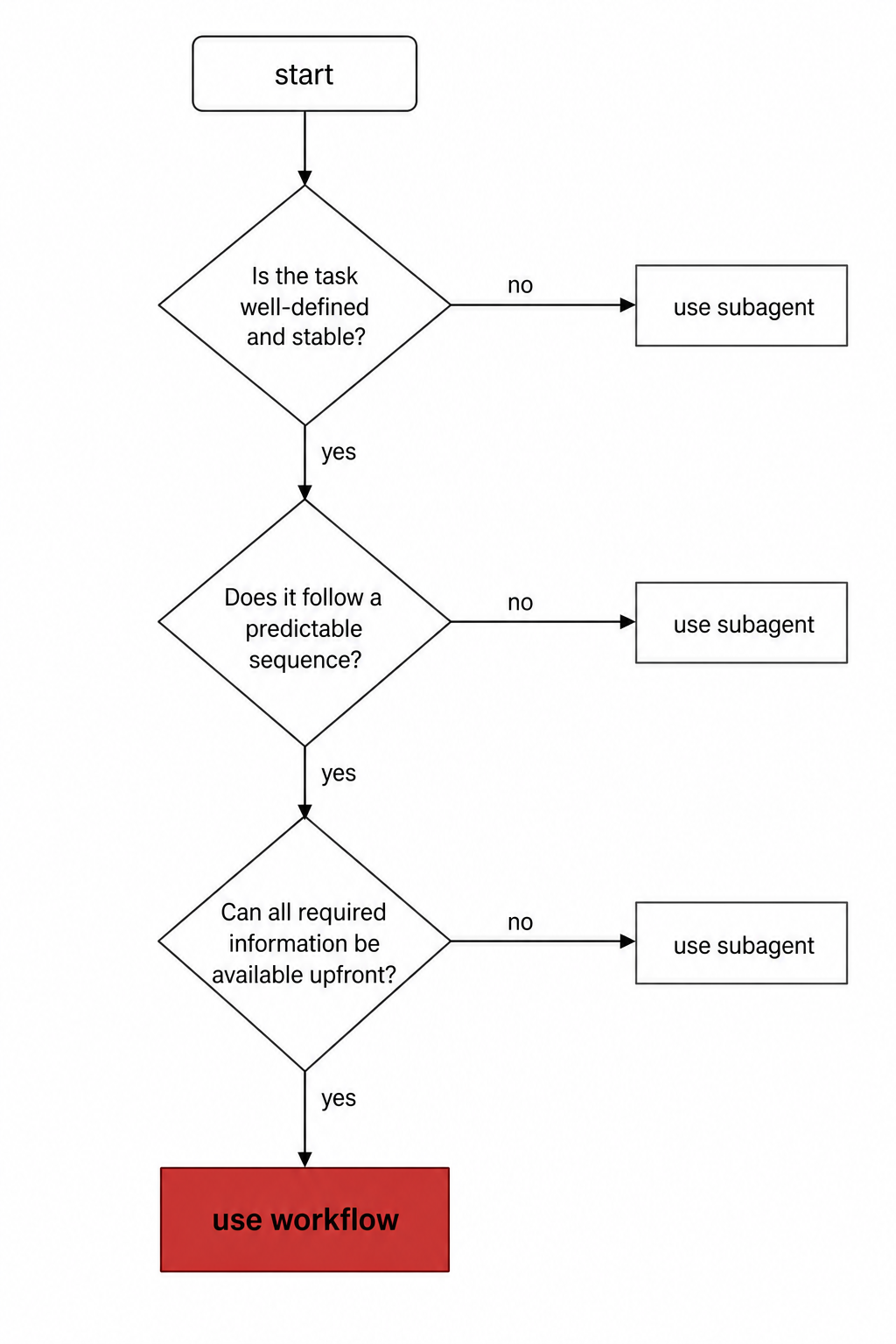
什么时候该用,什么时候别用
判据其实就一条:这活需要的 agent 数量,一个对话窗口还协调得过来吗?协调得过来,subagent 就够了;协调不过来,或者你想把编排沉成一段能读、能重跑的脚本,才上 workflow。
| 适合 | 不适合 |
|---|---|
| 全库扫一遍 bug / 安全审计 | 改一个函数、修一个明确的 bug |
| 500 个文件的迁移 | 问一句话就能答的事实查询 |
| 要把多个来源交叉核对的调研 | 需要你中途拍板、分阶段签字的流程 (workflow 跑起来不能中途接受输入) |
| 值得从几个独立角度各起一版的硬方案 | 重构 / 文档 / 改名 / 升依赖这类顺手活 |
有个反直觉的点:workflow 跑起来不能中途要你输入,只有 agent 的权限弹窗能暂停它。所以"做到一半让我看一眼再决定"的流程,不要塞进一个 workflow——把每个阶段拆成各自的 workflow,你在阶段之间签字。
三种触发方式
1. prompt 里带 workflow 这个词。不改会话的 effort,只把这一个任务当 workflow 跑。Claude Code 会把这个词高亮出来,然后给你写脚本。误触了按 alt+w 取消。
Run a workflow to audit every API endpoint under src/routes/ for missing auth checks2. ultracode 模式。/effort ultracode 把 xhigh 推理 + 自动编排打开。开了之后 Claude 自己判断每个任务要不要起 workflow——一个请求可能连开三个:一个搞懂代码、一个改、一个验。代价是整个会话每个任务都更费 token、更慢,回到日常活记得 /effort high 降回来。
3. 现成的 / 保存的命令。/deep-research 是内置的。你自己跑出一个满意的 workflow,在 /workflows 里选中按 s 就能存成命令——存进项目 .claude/workflows/(跟仓库共享)或家目录 ~/.claude/workflows/(只你自己用),下次直接 /<名字> 调。每次 review 跑同一套编排,这个很香。
成本和那几条硬限制
workflow 会 spawn 一堆 agent,一次跑掉的 token 明显比在对话里把同一件事做完要多,而且照常计入你套餐的用量和限流。该知道的边界:
| 最多 16 个并发 agent | CPU 核少的机器更少;超出的排队,跑完一个补一个 |
| 单次最多 1000 个 agent | 跑飞循环的兜底 |
| 不能中途输入 | 只有 agent 权限弹窗能暂停;要分段签字就拆成多个 workflow |
| 脚本本身不碰文件系统/shell | 读写和跑命令都是 agent 干的,脚本只负责协调 |
| 同会话内可 resume | 已完成的 agent 返回缓存结果,其余 live 重跑;退出 Claude Code 再进就从头来 |
省钱的两个动作:大跑之前用 /model 确认一下别还挂在大模型上;描述任务时直接说"不吃重的阶段用小模型"——每个 agent 默认跟会话用同一个模型,除非脚本给某个阶段单独路由。
落地一句话
workflow 不是"更强的 subagent",是把编排这件事从 Claude 的临场判断里拿出来、固化成一段你能审、能重跑、能交叉验证的代码。所以它的甜区很清楚:规模大到一个窗口装不下、或者结论重要到值得让多个 agent 互相质证的活。日常改代码,老老实实让 Claude 单线程做,反而更快更省。
评论
评论发布后会立即公开,如触发规则可能被审核下架。